multi-core risc-v system
a complete RTL-design of a RISC-V multicore system
Multi-Core RISC-V System
Over the semester my partner and we completed a sequence of four interconnected lab assignments that collectively guided me from a low-level arithmetic unit to a full single- and multi-core system for our computer architecture course. Each lab built on the previous work, reinforcing hardware-software co-design, modularity, and performance engineering.
Iterative Integer Multiplier
In the first lab, we designed two versions of an integer multiplier: a baseline fixed-latency implementation and a variable-latency variant that dynamically exploits operand structure. we implemented both in Verilog (following the datapath/control split) and verified correctness via a testing harness. With directed tests and simulation we evaluated performance differences between the implementations. This lab introduced me to RTL modeling, val/rdy streaming interfaces, and modular design of arithmetic units.
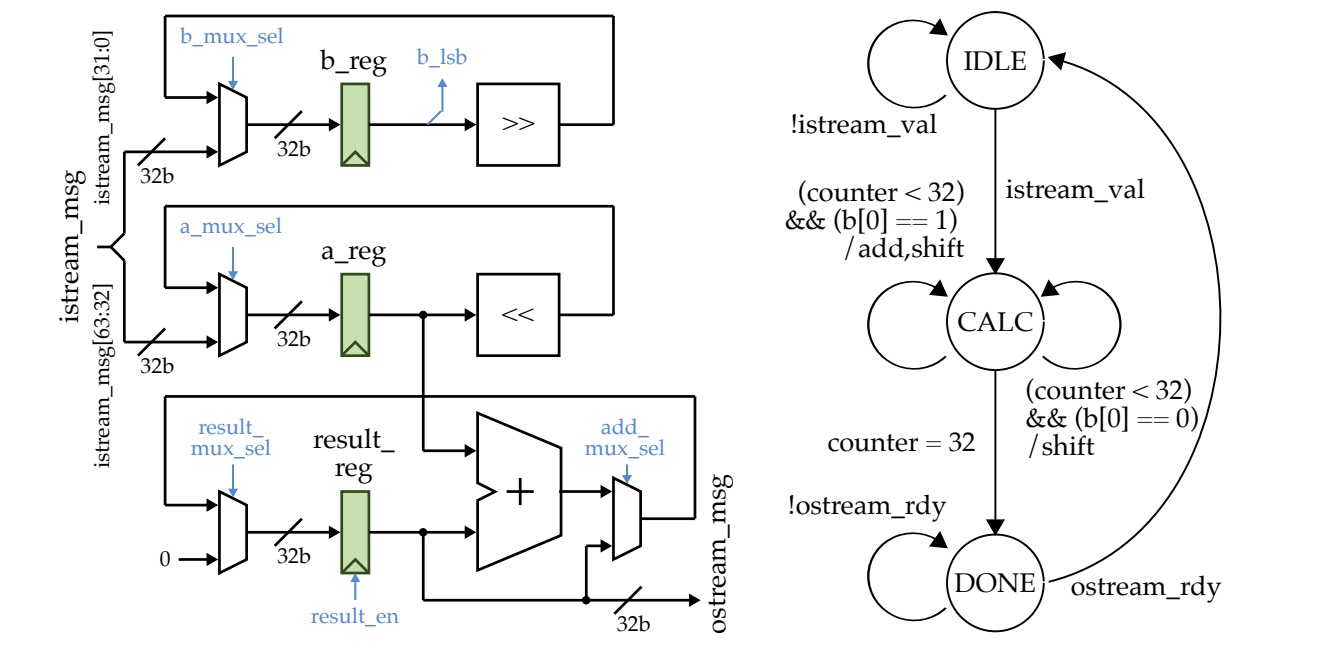
Pipelined Processor
In the second lab we built from my multiplier to implement two five-stage pipelined processor microarchitectures for the TinyRV2 subset: a stalling baseline and a bypass-enhanced alternative. we extended the earlier hardware to support instruction fetch, decode, execute, memory and write-back stages; addressed hazards and interfaced with instruction/data memories. we verified ~27 of the 34 TinyRV2 instructions and benchmarked both designs to quantify CPwe and pipeline efficiency. This lab deepened my understanding of ISA-microarchitecture mapping, pipeline hazards, and hardware/software interplay.
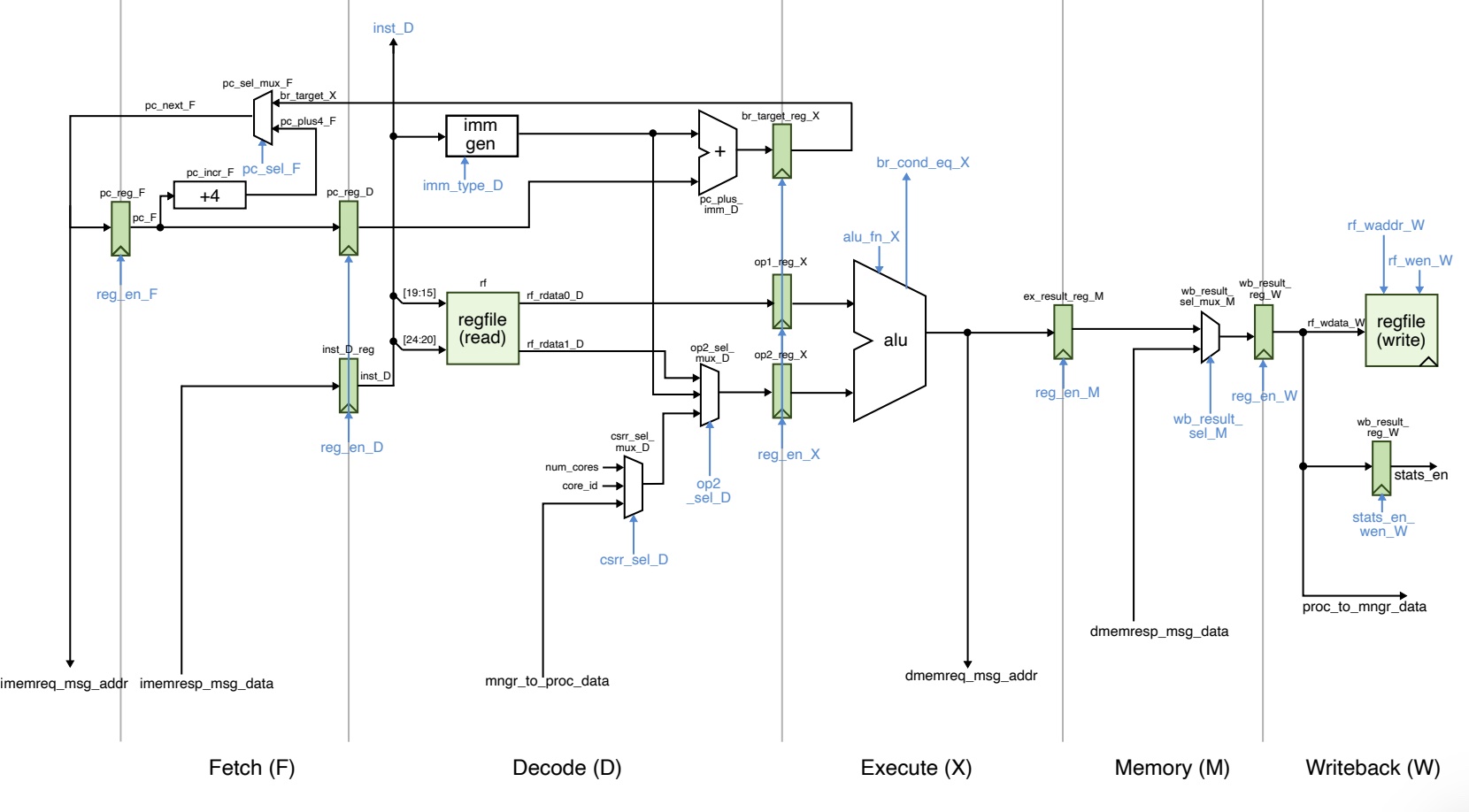
Blocking Cache
In the third lab we moved into the memory subsystem, designing two cache microarchitectures: a baseline direct-mapped write-back/write-allocate cache and an alternative two-way set-associative variant to reduce conflict misses. we decomposed datapath and control FSM modules in Verilog, leveraged the val/rdy streaming interface from prior labs, and conducted simulation and evaluation of hit/miss performance. This work emphasized memory-hierarchy design, FSM-based control, and the performance implications of associativity and policy decisions.

Single-Core and Multi-Core Systems
In the final lab we integrated all components: the multiplier, processor, cache(s), and network fabric into full systems. For the baseline we built a single-core system with private instruction and data caches and verified it by running a sorting microbenchmark in C. For the alternative we developed a multi-core system (ring network, banked shared data cache, private instruction caches) with multi-threaded software and measured scalability. This culminating lab reinforced system-level design, hardware/software co-verification, integration testing, and multicore trade-offs in a unified environment.
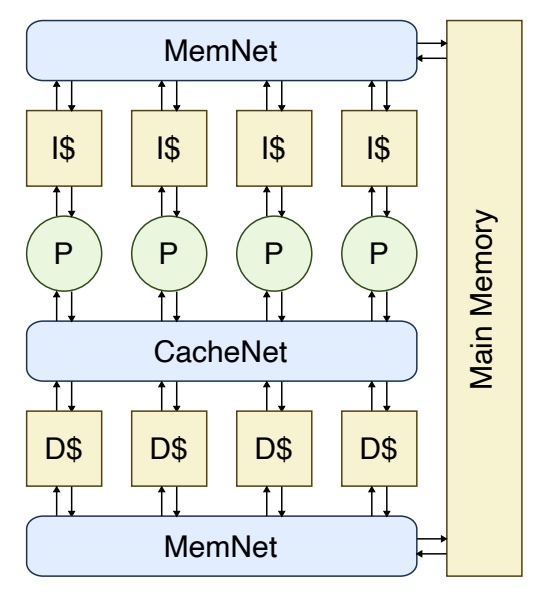
Conclusion
Across these four labs I progressed from arithmetic units to full systems, developing a robust design mindset: using modular RTL, layering abstraction levels, integrating hardware and software, and critically evaluating performance. This journey reinforced my interest in democratizing accelerator design—translating from individual hardware IPs to composable, scalable systems. The experience also sharpened my ability to reason across the hardware-software boundary, aligning clean abstractions with concrete implementations and performance metrics.